Subdomain Reconnaissance Made Easy

The information gathering phase of penetration testing is probably the most important part. This is where we build our understanding of the target, and get a general idea of how we may wish to attack. Subdomain reconnaissance is a critical skill to have in your tool belt, as it may reveal possible entry points that are less secure than the main customer facing application of an organization.
In this article we will cover Subdomain Reconnaissance techniques, and give an overall simple template to follow.
Why Learn Subdomain Reconnaissance?
If you are someone who wishes to learn more about Web Application Security, and inspires to have a future as either a Web Application Penetration Tester or Application Security Engineer, than you need to understand the importance of subdomain recon.
As web development has evolved to meet the demands of users, web applications have changed from the once standard monolithic to the microservice. What does this mean?
In a monolithic architecture, a single large computing platform is used to host a code base. This code base is usually tightly coupled, meaning that if a developer has to update a single component, then other components will also need to be updated. Monolithic architecture also coincides with the classic Client-Server model.
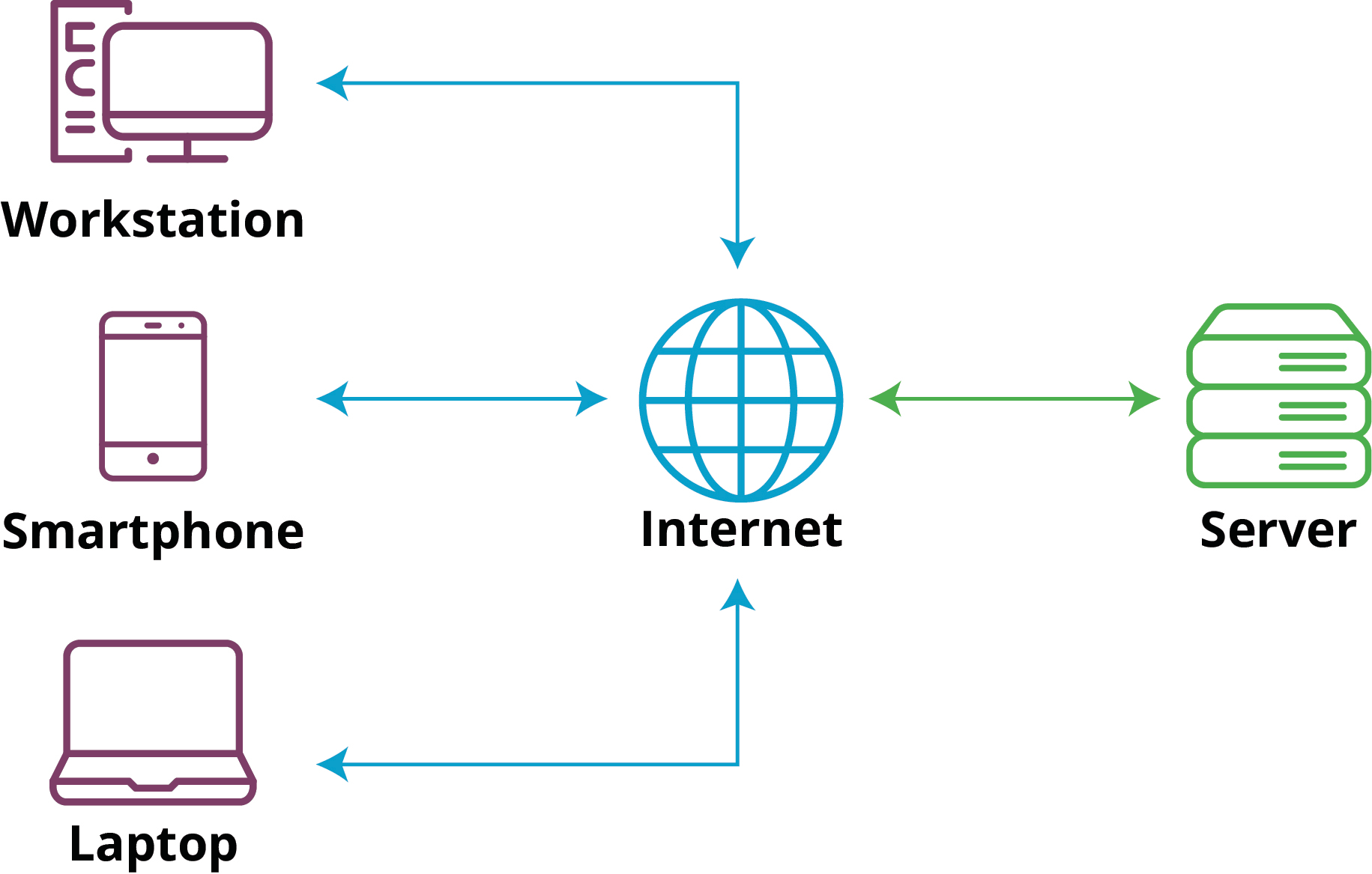
This means that most processing is done on the server for the duration of the session, which does not scale well as more clients connect. We have limited computing resources and slow responses from our server, which would degrade user experience.
From a penetration tester’s point of view, this means focusing your efforts on one server, often the www. These were the early days of web applications on the internet, but since then many have changed.
With the rise of Single-Page Applications written with popular JavaScript libraries such as React.js, Angular.js, and Vue.js, architecture has evolved to handle application state on the client, and breaking monolithic features up into dedicated services hosted on separate servers.
This is called microservice architecture, where the application is developed as separate code bases. This allows for loose coupling, and whenever a developer makes an update to one code base, other code bases will not need to be updated.
We also get faster responses since each service is hosted on separate hardware. If one service is dealing with a lot of requests, it won't slow down other services.
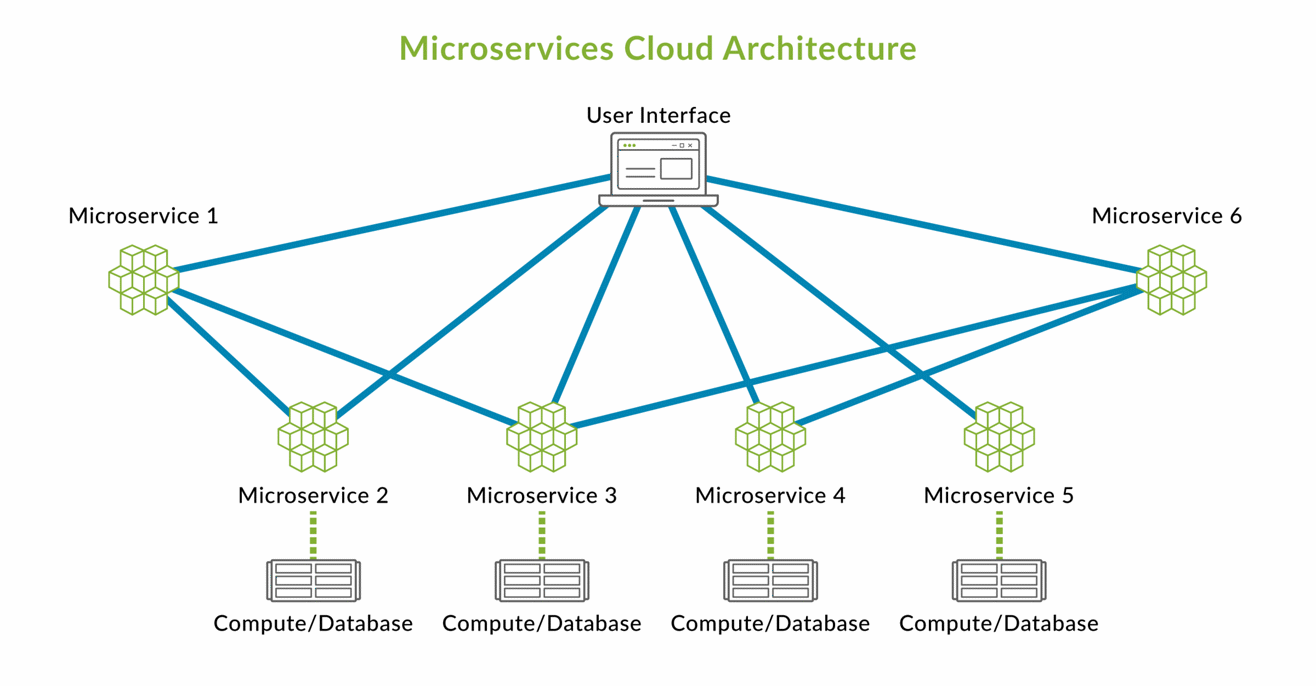
These services are called using Restful or CRUD API's, where we make http requests either to create, read, update, or delete data. These requests can be made to url's such as the following:
https://customers.example.com
https://specials.example.com
https://inventory.example.com
https://cart.example.com
https://auth.example.com
https://session.example.com
At this point, an “ahh, I see” should have gone off in your head, because we see that each of these services are hosted at different subdomains- each with possible vulnerabilities that could be exploited by a threat actor. Just like asset management, to know how to secure an asset, you need to know what you are protecting.
Now that we understand the importance of subdomain recon, let's learn some techniques.
Subdomain Reconnaissance Techniques
Subdomain Reconnaissance Techniques fall either under Manual or Automated. Automated techniques should be the last resort, because they are easily detectable.
Manual Techniques
The manual techniques we will cover are:
Using the Browser's built-in Network Analyzer Tool
Search Engines
Accidental Archives
Twitter API
Zone Transfer Attacks
The Browser's Built-In Network Analysis
Most browsers today come with built-in Developer Tools that offer a set of utilities to aid web developers in debugging, testing, and optimizing their web applications. These utilities allow developers to inspect the structure and layout of a web page, analyze network activity, debug JavaScript code, and modify CSS styling of elements.
Generally, it is easy to conduct recon using the Network Analyzer. We simply open the Developer Tools and browse the website as if you were just an everyday user. Of course, as we use the application, we make note of any network requests that reveal clues on how the application is architected.
We will visit an easy application to display, go to https://www.wikipedia.org/ , in your Chrome Browser.

Right-Click on the Page, and scroll down to Inspect and Click it.

The Developer Tools will open, and Navigate to the network tab.

Press CRTL+R, and you'll see the network request being made, as the browser reloads the page.

We can see the initial HTTP GET Request made to www.wikipedia.org, now lets use it as if we were an everyday user. In search field type, in California.

We can see network requests being made as we type, to search for calls we are interested in type ".wikipedia" in the filter text field.

Click one of the request to inspect it

Looking at this request, we can see that it has a subdomain at en.wikipedia.org, annotate this, and we will move onto using the Search Engines for recon next.
Search Engines
Google is the most popular search engine in the world, and has indexed more data than any other search engine. Just googling an organization by itself may not yield practically useful information due to the sheer amount of data that is returned. We need to have some method to find exactly what we are looking for.
Google thought the same exact thing, and created search operators. Search operators are special characters or commands that can be added to a search query to refine and customize the search results. These operators give us the ability to narrow down our search results. We will focus on the two operators site: and -inurl:
The site: operator is used to specify that search results should come from a particular website or domain.
The -inurl: operator is used to specify that search should not contain a term or phase in the URL.
Now let's continue to do recon on wikipedia.org.
Go to Google and type in the search bar site:.wikipedia.org and -inurl:www, we specify we don't want www because this is the primary user facing web application.

We see that we get search results for commons, en, and it. Now place in the search site:.wikipedia -inurl:www -inurl:commons -inurl:en -inurl:it.

As you find more subdomain continue to use -inurl: search operator to exhaustively find as many subdomains as you can. This is a tedious process, but is a simple technique.
Accidental Archives
There are public Internet Archiving utilities such as https://archive.org/ that periodically take snapshots of websites on the internet, and allow you to visit these websites even years later. The goal of Internet Archiving tools is to preserve the history of the Internet. Though a noble cause, this is a goldmine for us as we conduct recon on our target.

Though our search engine technique is great for current data, relevant historical data can be found with archives. They are practically useful if we know a point in time when a website shipped a major release or had a security vulnerability disclosed.
When looking for subdomains, the historical archives disclose this information in form of hyperlinks that were once exposed through HTML or JS but are no longer on the current version.
If we use Archive.org, all we simply need to do is "View Source" to do recon.
Twitter API
Twitter the number one place on the Internet for TMI, it's no wonder it made our list as a valuable source for Subdomain Recon. For simplicity we will focus on the Twitter API, even though many other social media platforms have APIs.
Many organizations use social media to advertise to users. Some of these posts could have advertisements about limited specials where you sign up to win prizes, that point to a web application portal such as signup.example.com
Using APIs are pretty simple, you sign up, and choose a tier. These usually differ in the number of requests you can make to the API in a certain time frame. Read the twitter API Docs to find out (https://developer.twitter.com/en/docs/twitter-api).
Twitter has an API endpoint that we can use to search for tweets from a company. Use the following node.js code as an example to get the tweets.

Now that we have gotten tweets from the company, we can use a regex within the tweet.text to find a tweet that contains a Sub-domain from the company. Let's update the code

Zone Transfers Attacks
A Zone Transfer Attack is an attack targeting Domain Name System servers. In a zone transfer attack, an attacker attempts to get a full copy of the DNS zone file from a DNS Server. The zone file contains information about domain names, IP addresses, and other DNS records associated with a specific domain.
The attack exploits misconfigurations in DNS servers that allow unauthorized zone transfers. By obtaining the zone file, we will be able to find subdomains that belong to an organization.
Performing Zone Transfer is easy with dig, the following is an example, note @nameserver is the DNS server you wish to attempt a transfer on:

Zone Transfer Attacks nowadays generally fail because most DNS servers are properly configured to protect against it. This is considered low-hanging fruit, but it is still a valuable skill to have.
Automated Techniques
As previously mentioned, automated techniques should be saved as a last resort, as they are easily detectable. The automated techniques we will cover are:
Brute Forcing Subdomains
Dictionary Attacks
Brute Forcing Subdomains
In our process of finding subdomains, as a last resort we can use brute force. When using brute force, we need to be conscious of how we conduct them, since many web applications have security mechanisms against it and devices on the internet may be logging our traffic. Brute force is also considerably time consuming because we must try every possible combination.
We can use asynchronous requests to fire off all requests at once, instead of waiting for each individual response to complete. This will help reduce the time it takes to brute force domains.
The following script can be used for brute forcing:

Dictionary Attacks
A dictionary attack is not only used for password cracking, but it is also a valuable skill to have for subdomain recon. A dictionary attack involves systematically trying a list of commonly used or likely subdomain names in an attempt to find valid subdomains associated with a domain. This attack relies on the attacker having a dictionary or wordlist containing potential subdomain names, such as common words, phrases, abbreviations, or variations that are commonly used in domain naming conventions.
The attacker iterates through the list of potential subdomain names, appending each one to the target domain and performing DNS resolution to check if the subdomain exists. If the DNS resolution is successful (i.e., the subdomain resolves to an IP address), the attacker considers the subdomain valid.
Dictionary attacks are well known, and have often been automated already, one tool we can use is Sublist3r. Sublist3r is a Python-based tool designed to enumerate subdomains of websites using various search engines. It also allows for subdomain enumeration using a wordlist.
Here is an example using Sublist3r:

In the above example, the -e param would specify the path of the wordlist you wish to use.
Summary
In summary, subdomain reconnaissance techniques play a vital role in penetration testing by uncovering hidden assets, expanding the attack surface, identifying vulnerabilities, facilitating lateral movement, and informing risk assessment. A comprehensive understanding of subdomains helps penetration testers simulate real-world attack scenarios, uncover critical security issues, and provide actionable recommendations for improving the overall security posture of the target organization.



